
DevOps - a buzzword that is becoming a mouthpiece in many companies lately. From "corporate disruption" and "agile everything", the spotlight of the IT industry had passed to DevOps in recent years. How to reconcile the DevOps vision with the reality of enterprises.
DevOps is the acronym for a set of methods, tools, and processes for automating the delivery of software or services to an organization. DevOps can support services over a longer period of time, looking at the entire life of the software. These include, for example, installation, configuration, error handling, and also deployment to users. Issues such as rapid system availability, adherence to update cycles, and even deployment of new infrastructure fall into this category.
Automatic load monitoring for Atlassian plugin updates
Although most Atlassian Marketplace plugins are thoroughly tested in terms of stability, performance, and load, it often happens that Jira and Confluence instances require additional resources during an update.
Especially if you perform custom developments in your instance, this visibility is indispensable.
Additional load becomes problematic when it slows down the instance and has a noticeable impact on user experience and system stability. In the worst case, this leads to a complete failure of the productive systems and downtimes.
With the right tools and strategies from the methodology grouped under DevOps, this is a thing of the past:
- With continuous monitoring and data collection you can directly see the impact of updates on your instance
- Respond to performance degradation by allowing updates to be rolled back.
- With Blue-Green Deployments and DevOps, your system can also be tested for performance by, for example, successively letting users onto the more up-to-date system (these are so-called canary releases - you can read more about this below).
Fast recovery during downtimes
At leading Fortune 1000 companies, the average total cost of unplanned system outages per year is $1.25 billion to $2.5 billion. This means that every hour a system is down costs 100,000 $.
These costs are not only annoying, but can usually be easily avoided. DevOps offers a framework that easily reduces possible downtimes to a minimum and uses technologies to be back online in the shortest possible time in the event of a system failure.
DevOps helps minimize downtime and speed up recovery by using Spinnaker technology at XALT. This makes it possible to quickly and easily jump back to previous versions of the system without losing important data in the database.
System availability within minutes
In software development, a wide variety of systems are often required for development or testing without warning. These systems or IT infrastructure is usually configured manually without DevOps. However, manual configurations usually take a lot of time and are more error-prone.
With automatic infrastructure provisioning (using IaC and DevOps), all parts of your IT infrastructure (e.g. servers, databases, load balancers and systems) will not be manually configured or managed by developers each time in the GUI from the cloud provider.
Benefits of Infrastructure as Code:
- Lower costs
- Faster deployments
- Fewer errors
- Better infastructure consistency
- No configuration deviations
- Examples of IaC tools (Ansible, Terraform, CloudFormation, Helm)
- IaC not only automates the process, but also serves as a kind of documentation of the correct procedure for deployments of the infrastructure.
For IaC, often already existing tools for server automation and configuration management can be used. In addition, there are also solutions here that have been developed specifically for IaC.
Availability of development systems and test systems
Developers are constantly testing new features, updates and bug fixes on development and test systems. And what influence or impact these "changes" have on the system.
However, these "changes" often have to be compared with each other in order to draw conclusions for recommendations for action. With the help of IaC, an unlimited number of development systems can be generated and deployed. For example, another Kubernetes cluster can be easily deployed, or Helm can be used to deploy another application.
By having several different development systems running simultaneously, your IT team can always make comparisons between systems without affecting your live system.
Using "Infrastructure as Code", new systems can also be booted up at any time within a few moments and used for development.
Furthermore, systems that are no longer required can be shut down at any time as soon as they are no longer needed.
Advantages of multiple development systems
- Comparison of multiple, but inherently different development systems in real time.
- Derivation of recommendations for action through analysis of the comparative data.
- Direct availability on demand of additional development systems through "Infrastructure as Code approach".
- Each developer or team has its own test system
Development systems are not comparable with the live system
Many developers have the problem that the system they use for development is often not comparable with the live system. Important parameters, plugins and integrations are often missing, or only an old data set is available.
So that your developers always have the current data set or a comparable system available, we rely on "Infrastructure as Code". This makes it possible to provide a system for development ad hoc. On the other hand, the live system is cloned and the current data set is used.
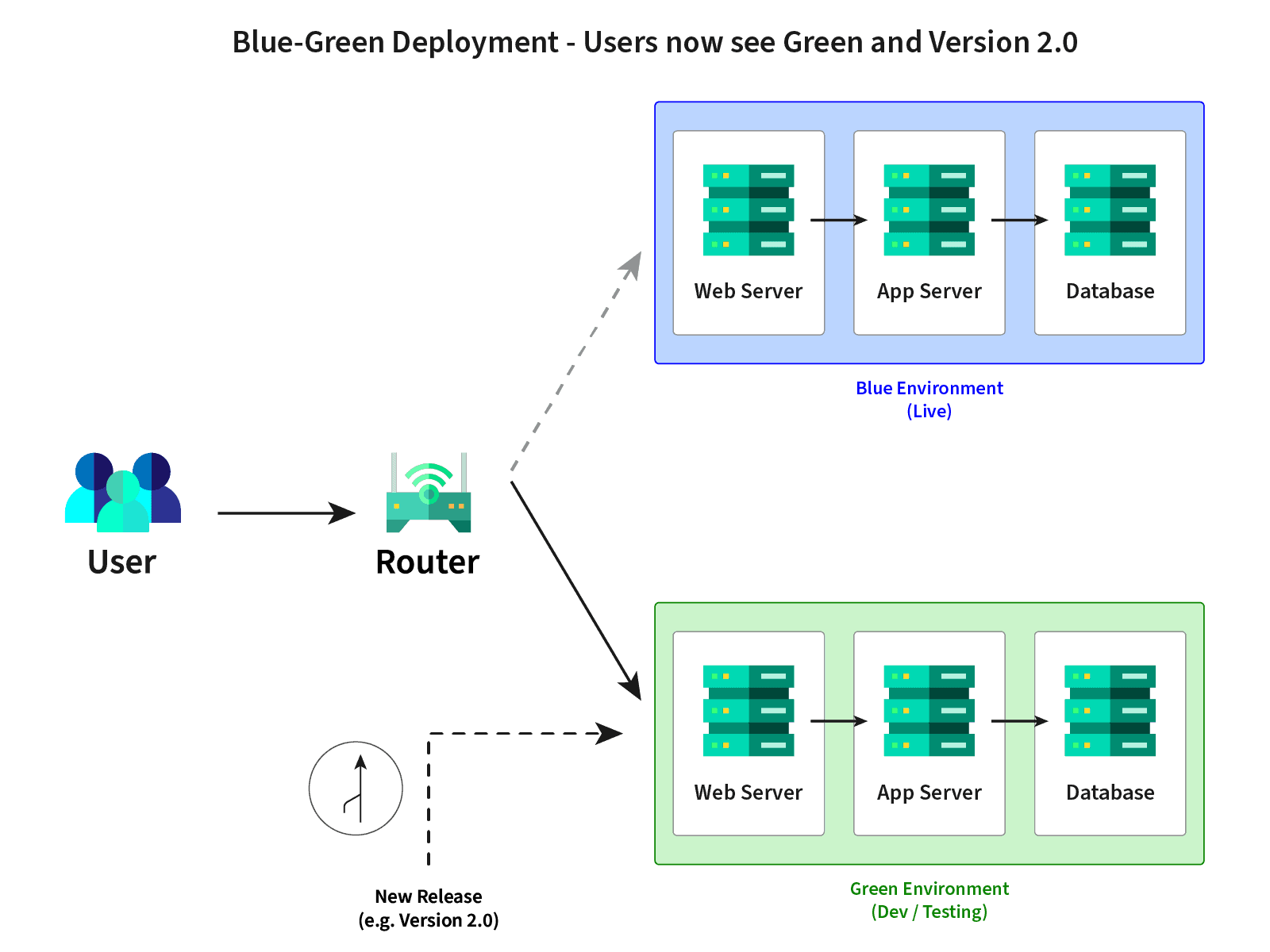
Afterwards, your developers can provide the cloned system with further features or update it. This means that the Blue-Green approach is used again at this point. The cloned system is then merged with the Green system. When the time has come, the productive system is switched from "Blue" to "Green".
The advantage of this approach is that your developers can not only always work on current and comparable systems, but the development systems can then be switched live. This saves you as a company not only a lot of time, but also a lot of resources and accelerates your processes.
Staging System corresponds to the Development System
Before a system goes live, it is usually submitted for acceptance via a staging environment. This usually gives the person responsible (or also the customer) the opportunity to convince themselves of the functionality of the new system, the update or feature integrations. In many cases, these staging environments are set up specifically for this purpose and are only needed for this purpose.
By using DevOps and the possibility to provide ad hoc systems, this problem can easily be eliminated. In addition, however, a development system can also be used as a staging system / environment and then published as an active and, above all, stable system via a so-called blue-green deployment.
Easy rollback to a previous version with blue-green and spinnaker
Even if updates, code changes or feature integrations have been tested several times, it happens again and again that systems do not work properly in active operation, contain bugs or the performance is not as hoped for. In this case, it is often only possible to roll back to the previous version to ensure the stability of the system and to have a functional system again. Afterwards it can be investigated why the product system did not work anymore.
Rollbacks take a lot of time without using Spinnaker or the Blue-Green approach, and cost a lot of money in terms of additional downtime.
That's why XALT uses the Spinnaker tool. Spinnaker is a multi-cloud continuous delivery platform for releasing software changes, which can store multiple versions of your systems.
This allows a previous version to be restored with just one click. This process is additionally accelerated using the Blue-Green approach. There are always one or more similar systems in circulation.
Automatic testing of new versions of external software (e.g. Jira and Confluence)
Your company probably uses some external software solutions that are installed on an AWS or Azure cloud instance. However, updates to these apps are out of your control. And updates can often lead to unwanted problems. For example, plugins or integrations stop working. REST API changes cause errors in individual connections to other tools. Or the update is simply not mature and leads to performance drops on your instance.
Example: Automatic testing of Confluence updates
To cope with the situation, a new branch with a copy of the main system is created and an update is performed before an update. The live system is not affected by this. Some tests are then performed in the new branch. Load tests to measure the performance. Regression tests to find out if all active plugins are compatible with the new Confluence version.
Automatic maintenance page in case of downtime or unavailability
You're probably familiar with it. You try to visit a website or web service and end up on a blank page with no information. Is this because of my connection, or is the server down?
Such situations are usually very unpleasant and often lead to several support requests to your service staff.
This problem can usually be solved with a simple maintenance page, which is automatically switched live in case of unavailability.
An effective way to automatically prepend maintenance pages can be as follows:
- At regular intervals an automatic System Health Check executed.
- If the health check is successful, the system continues to run.
- If the health check is not successful, the maintenance page is displayed and further information is provided for the user.
- The IT department then carries out a comprehensive test of the system. And makes it available to users again as quickly as possible.
Automatic testing of backups to ensure system stability
Normally, the database is shut down for a few moments before each backup so that no errors occur in the backup. Another problem that can occur is that data is lost when copying the database. If the system is then restored from this backup, a start-up is often not possible and leads to downtimes again and further restricts availability.
To avoid this problem, automatic backup tests are tested for integrity. A health check is performed and the backup is tested for completeness. If both of these tests are successful, the system is restarted and released for users.
With this approach we create a double safety precaution for the rollback to a previous version and achieve a higher availability of the productive systems.
Canary Releases - Successive system deployment for all users
Especially in systems with thousands or tens of thousands of concurrent users, it can happen that updates or new features lead to poor performance or availability. A widespread problem is that new features work smoothly in test environments. However, these are then only limited usable at full "load", or in the live system. New features usually have the peculiarity of wanting to be used quickly by a large number of users. It happens that the server or the app can not execute this rush. In the worst case, the system then crashes.
However, this problem can be solved by so-called canary releases. With the help of several systems running in parallel (Blue-Green), these features are successively released for users. This makes it possible to check whether the system withstands the load and maintains its integrity and stability. The advantage of this is that you can revert to the previous version at any time and your users will not notice any impact on availability.
Confluence: Read Only Version by Downtime, Update or Bugfix
Intranet and Wiki always available
It is always extremely annoying when important systems are temporarily unavailable. On the one hand for users, and on the other hand for your developers and Confluence / System Admins. Your users then no longer have the possibility to gather important information from your wiki, the collaboration with your team is limited and in the worst case, missing information has a negative impact on your business success.
However, we at XALT have found that most Confluence users "only" read the company wiki, but do not write their own posts or edit content.
The question that arises is, how do I provide my employees with all relevant information if Confluence fails?
Confluence offers a so-called "Read Only" version here. This is normally used when your admins activate the maintenance mode. The big advantage of this is that the entire wiki, including the database, is still available to all users.
However, the Read Only mode must always be activated manually first, which is difficult to do when the system is inactive.
Using the DevOps methodology, we can help you provide a read-only version automatically in case of downtime. This allows your employees to continue to access the system and obtain important information at any time.
Automatic update rollout in constant time intervals
In many companies, updates are applied manually to active systems and times are set in advance when an update will be applied.
Many updates run in the background and do not affect the availability of the system or only for short moments. However, some updates require systems to be shut down for several hours.
By implementing automation and using DevOps tools, these manual steps are a thing of the past.
At XALT, we use the Blue-Green deployment methodology and approach to ensure 99.95 % availability. And on the other hand, we use an approach that merges finished development systems with the "green" and inactive instance and publishes them at a fixed point in time, i.e. switches from blue to green.
This not only accelerates the time from development to deployment and offers your employees a real time advantage, but also ensures the possibility of a quick and easy rollback with the former Live System (Blue).
Do you recognize some of these problems in yourself and would like to get on top of the situation? Our experienced DevOps engineers will be happy to help you and give you initial recommendations on how you can integrate DevOps at an early stage.
For more information on DevOps, click here: DevOps Transformation


