
DevOps – ein Schlagwort, das in letzter Zeit in vielen Unternehmen Sprachrohr wird. Von “corporate disruption” und “agile everything” war das Rampenlicht der IT-Industrie in den letzten Jahren an DevOps übergegangen. Wie kann man die DevOps Vision mit der Realität der Unternehmen in Einklang bringen.
DevOps ist die Abkürzung für eine Reihe von Methoden, Tools und Prozessen zur automatisierten Bereitstellung von Software oder Services für ein Unternehmen. DevOps kann Services über einen längeren Zeitraum hinweg, das gesamte Leben der Software betrachtet, unterstützen. Diese beinhalten beispielsweise Installation, Konfiguration, Fehlerbehandlung und auch die Bereitstellung für die Nutzer. Themen wie schnelle Systemverfügbarkeit, Einhaltung von Update Zyklen und auch Bereitstellung neuer Infrastruktur gehören in diese Kategorie.
Automatisches Load Monitoring bei Atlassian Plugin Updates
Obwohl die meisten Atlassian Marketplace Plugins hinsichtlich Stabilität, Performance und Load auf Herz und Nieren getestet werden kommt es immer wieder vor, dass Jira und Confluence Instanzen bei einem Update zusätzliche Ressourcen benötigen.
Gerade wenn Sie in Ihrer Instanz custom developments durchführen, ist diese Sichtbarkeit unabdingbar.
Problematisch wird zusätzlicher Load dann, wenn dieser die Instanz verlangsamt und einen spürbaren Impact auf User Experience und System-Stabilität hat. Im schlimmsten Fall führt dies zu einem kompletten Ausfall der Produktiv-Systeme und Downtimes.
Mit den richtigen Tools und Strategien aus der unter DevOps zusammengefassten Methodologie gehört dies der Vergangenheit an:
- Mit stetigem Monitoring und Datenerhebung sehen Sie direkt den Einfluss von Updates auf Ihre Instanz
- Reagieren Sie auf Performance-Einbrüche, indem Updates rückgängig gemacht werden können.
- Mit Blue-Green Deployments und DevOps kann Ihr System zusätzlich auf Performance getestet werden, indem Beispielsweise sukzessive User auf das aktuellere System gelassen werden (Hierbei handelt es sich um sog. Canary Releases – mehr dazu erfahren Sie weiter unten).
Schnelle Recovery bei Downtimes
Bei führenden Fortune-1000-Unternehmen belaufen sich die durchschnittlichen Gesamtkosten für ungeplante Systemausfälle pro Jahr auf 1,25 Milliarden bis 2,5 Milliarden Dollar. Das bedeutet, dass jede Stunde in der ein System nicht erreichbar ist 100.000 $ kostet.
Diese Kosten sind nicht nur ärgerlich, sondern können meist einfach vermieden werden. DevOps bietet hier ein Framework das unkompliziert mögliche Downtimes auf ein Minimum reduziert und bei einem Systemausfall Technologien verwendet, um in kürzester Zeit wieder Online zu sein.
DevOps hilft Downtimes zu minimieren und die Recovery zu beschleunigen, indem wir bei XALT auf die Technologie von Spinnaker setzen. Damit ist möglich schnell und einfach auf vorherige Versionen des Systems zurückzuspringen, ohne dass dabei wichtige Daten in der Datenbank verloren gehen.
Systemverfügbarkeit innerhalb weniger Minuten
In der Software-Entwicklung werden die verschiedensten Systeme oftmals ohne Vorwarnung zur Entwicklung oder Testen benötigt. Diese Systeme bzw. IT-Infrastruktur wird ohne DevOps normalerweise manuell konfiguriert. Manuelle Konfigurationen benötigen jedoch meist viel Zeit und sind fehleranfälliger.
Durch eine automatische Infrastruktur-Provisionierung (mit IaC und DevOps) werden alle Teile Ihrer IT-Infrastruktur (z.B. Server, Datanbanken, Load-Balancer und Systeme) von Entwickler:innen nicht jedes Mal manuell in der GUI vom Cloud Provider konfiguriert oder verwaltet werden.
Vorteile von Infrastructure as Code:
- Geringere Kosten
- Schnellere Deployments
- Weniger Fehler
- Bessere Infastrukturkonsistenz
- Keine Konfigurationsabweichungen
- Beispiele für IaC-Tools (Ansible, Terraform, CloudFormation, Helm)
- IaC automatisiert nicht nur den Prozess, sondern dient auch als eine Art Dokumentation der korrekten Vorgehensweise bei Deployments der Infrastruktur
Für IaC können häufig bereits vorhanden Tools für die Serverautomatisierung und das Konfigurationsmanagement genutzt werden. Zusätzlich gibt es hier auch Lösungen, die speziell für IaC entwickelt wurden.
Verfügbarkeit von Entwicklungssystemen und Testsystemen
Entwickler:innen testen ständig neue Features, Updates und Bugfixes auf Entwicklungs- und Testsystemen. Und welchen Einfluss bzw. Auswirkungen diese “Änderungen” auf das System hat.
Doch oft müssen diese “Änderungen” miteinander verglichen werden um daraus Rückschlüsse für Handlungsempfehlungen ziehen zu können. Mit Hilfe von IaC kann eine unbegrenzte Anzahl von Entwicklungssystemen generiert und bereitgestellt werden. Beispielsweis kann viel leicht einer weiteres Kubernetes Cluster oder mit Helm eine weiter Applikation deployed werden.
Indem nun mehrere verschiedene Entwicklungssysteme simultan aktiv sind, kann Ihr IT-Team stets Vergleiche zwischen den einzelnen Systemen ziehen, ohne dass Ihr produktiv System (Live System) davon beeinträchtigt wird.
Über den Einsatz von “Infrastructure as Code” können zudem zu jederzeit innerhalb von wenigen Augenblicken neue Systeme hochgefahren werden, die zur Entwicklung verwendet werden.
Weiterhin können nicht mehr benötigte Systeme jederzeit heruntergefahren werden, sobald diese nicht mehr benötigt werden.
Vorteile von mehreren Entwicklungssystemen
- Vergleich von mehreren, aber in sich verschiedenen Entwicklungssystemen in Echtzeit.
- Ableitung von Handlungsempfehlungen durch Analyse der Vergleichsdaten.
- Direkte Verfügbarkeit bei Bedarf von weiteren Entwicklungssystemen durch “Infrastructure as Code Ansatz”.
- Jeder Entwickler bzw. Team hat sein eigenens Testsystem
Entwicklungssysteme sind nicht mit dem Live System vergleichbar
Viele Entwickler haben das Problem, dass das System, welches Sie für die Entwicklung verwenden oftmals nicht mit dem Live System vergleichbar ist. Dabei fehlen oft wichtige Parameter, Plugins und Integrationen, oder es ist nur ein alter Datensatz verfügbar.
Damit Ihre Entwickler stets mit dem aktuellen Datensatz, bzw. ein vergleichbares System zur Verfügung haben, setzen wir auf „Infrastructure as Code“. Damit ist es möglich ad hoc ein System zur Entwicklung bereitzustellen. Zum anderen wird das Live System geklont und der aktuelle Datensatz genutzt.
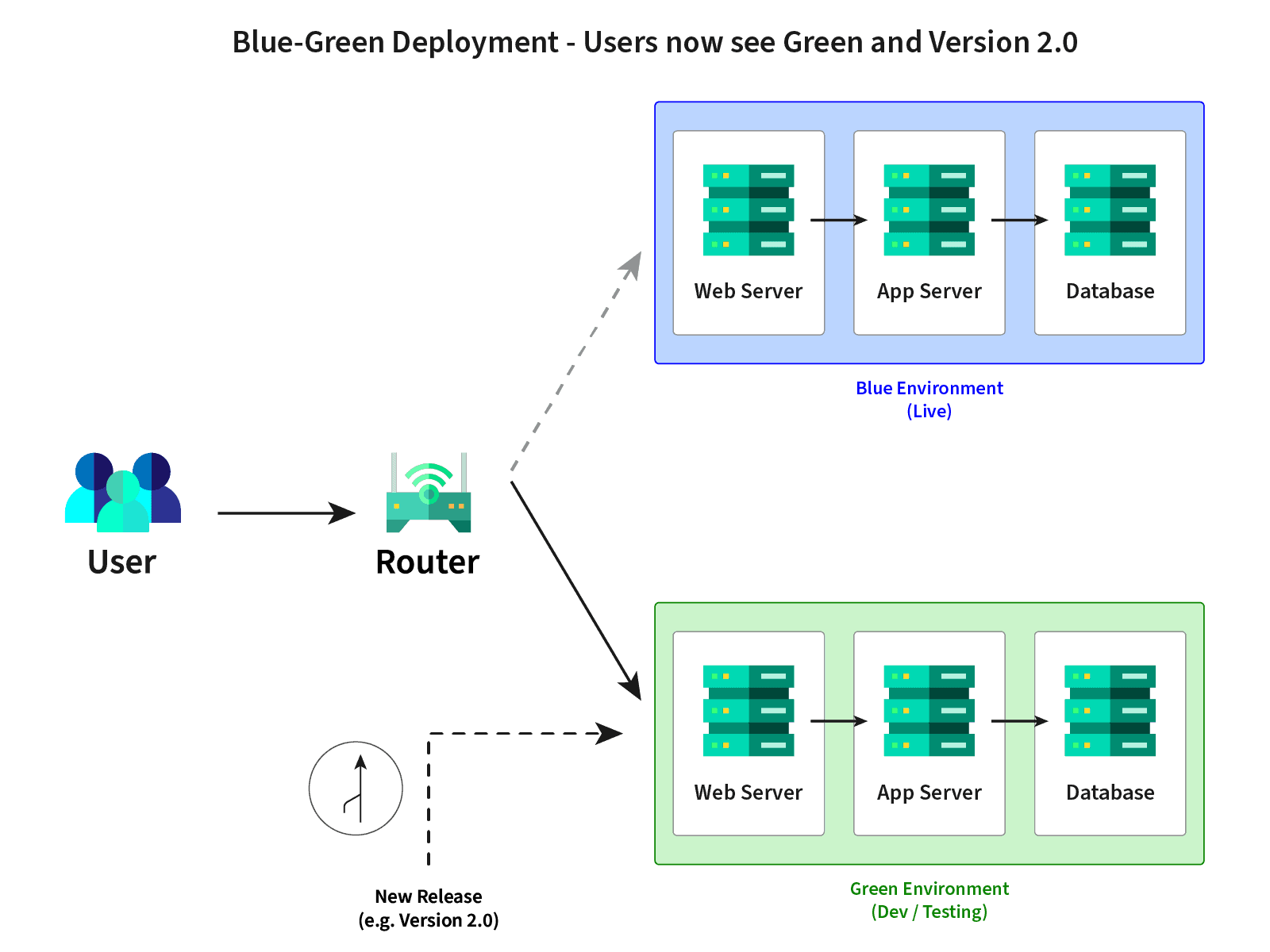
Anschließend können Ihre Entwickler das geklonte System mit weiteren Features versehen oder updaten. Damit kommen an dieser Stelle wieder der Blue-Green Ansatz zum Einsatz. Das geklonte System wird anschließend mit dem Green System zusammengefügt (merge). Ist die Zeit nun gekommen, wird das Produktiv System von „Blue“ auf „Green“ umgestellt.
Der Vorteil in dieser Vorgehensweise liegt also vor allem darin, dass Ihre Entwickler:innen nicht nur immer an aktuellen und vergleichbaren Systemen arbeiten können, sondern die Enwtwicklungsysteme anschließend Live geschaltet werden können. Damit sparen Sie sich als Unternehmen nicht viel Zeit, sondern auch einiges an Ressourcen und beschleunigen Ihrer Prozesse.
Staging System entspricht dem Development System
Bevor ein System live geht, wird meist über eine Staging Umgebung zur Abnahme vorgelegt. Damit wird in der Regel dem Verantwortlichen (Oder auch Kunden) die Möglichkeit gegeben, sich von der Funktionalität des neuen Systems, des Updates oder Feature Integrationen zu überzeugen. In einer Vielzahl der Fälle werden diese Staging Umgebungen eigens dafür aufgesetzt und nur dafür benötigt.
Durch die Verwendung von DevOps und der Möglichkeit ad hoc System zur Verfügung zu stellen, lässt sich dieses Problem einfach aus der Welt schaffen. Zusätzlich kann allerdings ein Entwicklungssystem auch als Staging-System / Umgebung verwendet werden und anschließend über ein sog. Blue-Green Deployment als aktives und vor allem stabiles System veröffentlicht werden.
Einfaches Rollback auf eine vorherige Version mit Blue-Green und Spinnaker
Selbst wenn Updates, Code-Änderungen oder Feature-Integrationen mehrmals getestet wurden, kommt es immer wieder vor, dass System im aktiven Betrieb nicht richtig funktionieren, Bugs enthalten oder die Performance nicht so ist wie erhofft. In diesem Fall ist oft nur noch möglich ein Rollback auf die vorherige Version vorzunehmen, damit die Stabilität des Systems zu gewährleisten und ein wieder funktionsfähiges System zu haben.. Anschließend kann investigiert werden, weshalb das Produkt System nicht mehr funktionierte.
Rollbacks benötigen ohne die Verwendung von Spinnaker oder den Blue-Green Ansatz viel Zeit und kosten in Form von zusätzlichen Downtimes viel Geld.
Bei XALT kommt deshalb das Tool Spinnaker zum Einsatz. Spinnaker ist eine Multi-Cloud Continuous Delivery Plattform für die Freigabe von Softwareänderungen, welche mehrere Versionen Ihrer Systeme speichern kann.
Damit kann eine vorherige Version mit nur einem Klick wiederhergestellt werden. Beschleunigt wird dieser Vorgang zusätzlich unter Verwendung des Blue-Green Ansatzes. Dabei sind stets ein oder mehrere ähnliche Systeme im Umlauf.
Automatisches Testen neuer Versionen externer Software (z.B. Jira und Confluence)
Ihr Unternehmen setzt vermutlich einige externe Software-Lösungen ein, welche auf einer AWS oder Azure Cloud Instanz installiert sind. Updates dieser Apps liegen jedoch nicht in Ihrer Hand. Und können oft bei Updates zu unerwünschten Problemen führen. Zum Beispiel funktionieren Plugins oder Integrationen nicht mehr. REST API Änderungen führen zu Fehlern in individuellen Anbindungen an andere Tools. Oder das Update ist schlicht nicht ausgereift und führt zu Performance-Einbrüchen auf Ihrer Instanz.
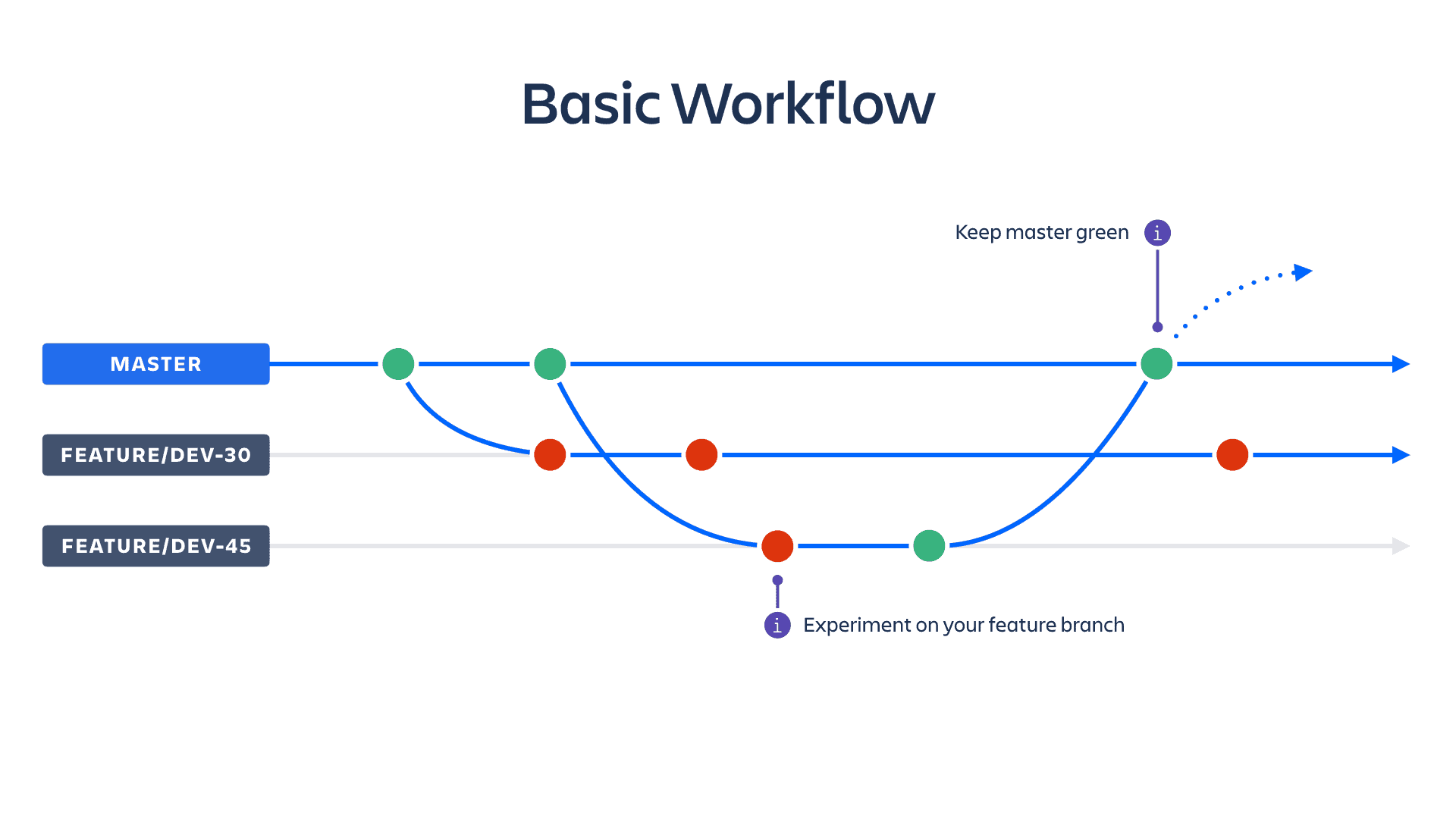
Beispiel: Automatisches testen von Confluence Updates
Um der Lage Herr zu werden, wird bereits vor einem Update eine neue Branch mit einer Kopie des Hauptsystems erstellt und ein Update durchgeführt. Das Live System wird dadurch nicht beeinträchtigt. In der neuen Branch werden anschließend einige Tests durchgeführt. Load Tests zum Messen der Performance. Regression Tests um herauszufinden, ob alle aktiven Plugins mit der neuen Confluence Version kompatibel sind.
Automatische Maintenance Seite bei Downtime oder Nicht-Verfügbarkeit
Sie kennen es sicher. Sie versuchen eine Webseite oder Webservice zu besuchen und landen auf einer blanken Seite ohne Informationen. Liegt dies an meiner Verbindung, oder ist der Server nicht erreichbar?
Solche Situationen sind meist sehr unangenehm und führen oftmals zu etlichen Supportanfragen an Ihre Service-Mitarbeiter.
Dabei lässt sich dieses Problem meist mit einer einfachen Maintenance Seite lösen, welche bei Nicht-Verfügbarkeit automatisch live geschaltet wird.
Ein effektives Vorgehen um Maintenance Seiten automatisch vorzuschalten kann wie folgt aussehen:
- In regelmäßigen Abständen wird ein automatischer System Health Check ausgeführt.
- Ist der Health Check erfolgreich, wird das System weiter ausgeführt.
- Ist der Health Check nicht erfolgreich, wird die Maintenance Seite vorgeschaltet und weitere Informationen für den User bereitgestellt.
- Anschließend führt die IT-Abteilung einen umfassenden Test des Systems durch. Und stellt es für die User schnellstmöglich wieder bereit.
Automatisches testen von Backups, um die System-Stabilität zu gewährleisten
Im Normalfall wird vor jedem Backup die Datenbank für wenige Augenblicke heruntergefahren, damit keine Fehler im Backup entstehen. Ein weiteres Problem, dass entstehen kann, ist dass beim Kopieren der Datenbank Daten verloren gehen. Wir dieses Backup anschließend das System aus diesem Backup wiederhergestellt ist oft ein Hochfahren nicht möglich und führt erneut zu Downtimes und schränkt die Verfügbarkeit weiter ein.
Um dieses Problem zu vermeiden, werden automatische Backup Test auf Integrität getestet. Dabei wird ein Health Check durchgeführt und das Backup auf Vollständigkeit getestet. Sind beide dieser Tests erfolgreich, wird das System wieder hochgefahren und für Benutzer:innen freigegeben.
Mit dieser Vorgehensweise schaffen wir eine doppelte Sicherheitsvorkehrung für das Rollback auf eine vorherige Version und erzielen eine höhere Verfügbarkeit der Produktiv-Systeme.
Canary Releases – Sukzessive Systembereitstellung für alle User
Vor allem bei System mit tausenden oder zehntausenden von gleichzeitigen Nutzern:innen, kann es vorkommen, dass Updates oder neue Features zu schlechter Performance oder Verfügbarkeit führen. Ein weiterverbreitetes Problem dabei ist, dass neue Features zwar in Testumgebungen reibungslos funktionieren. Diese dann aber bei vollem „Load“, bzw. im Live System nur eingeschränkt Nutzerbar sind. Neue Features, haben meist die Eigenart schnell von einer Vielzahl von Usern genutzt werden zu wollen. Dabei kommt es vor, dass der Server bzw. die App diesen Ansturm nicht ausführen kann. Im schlimmsten Fall stürzt das System dann ab.
Jedoch kann dieses Problem über sog. Canary Releases gelöst werden. Mit Hilfe von mehreren parallel laufenden System (Blue-Green) werden diese Features sukzessive für Nutzer:innen freigeschaltet. Dadurch kann überprüft werden, ob das System dem Load standhält und seine Integrität und Stabilität beibehält. Der Vorteil darin liegt, dass zu jederzeit zur vorherigen Version zurückgekehrt werden kann und Ihre User keinen Impact auf Verfügbarkeit erkennen können.
Confluence: Read Only Version by Downtime, Update oder Bugfix
Intranet und Wiki stets Verfügbar
Es ist immer äußerst ärgerlich, wenn wichtige Systeme zeitweise nicht mehr verfügbar sind. Zum einen für User, und zum anderen für Ihre Entwickler und Confluence / System Admins. Ihre User haben dann nicht mehr die Möglichkeit sich wichtige Informationen aus Ihrem Wiki zusammenzusuchen, die Zusammenarbeit mit Ihrem Team ist eingeschränkt und im schlimmsten Fall haben fehlende Informationen negative Auswirkungen auf Ihren Geschäftserfolg.
Wir bei XALT haben allerdings die Erfahrung gemacht, dass die meisten Confluence User, „nur“ im Firmen-Wiki lesen, aber keine eigenen Beiträge schreiben oder Inhalte editieren.
Die Frage, die sich damit stellt, ist also, wie stell ich meinen Mitarbeitern:innen alle relevanten Informationen bereit, wenn Confluence einmal ausfällt.
Confluence bietet hier eine sog. „Read Only“ Version an. Diese kommt normalerweise zum Einsatz, wenn Ihre Admins den Maintenance Modus aktivieren. Der große Vorteil darin liegt, dass stets das gesamte Wiki inkl. Datenbank weiterhin für alle User verfügbar ist.
Allerdings muss der Read Only Modus zunächst stets manuell aktiviert werden, was sich bei einem inaktiven System allerdings nur schwer bewerkstelligen lässt.
Unter Verwendung der DevOps Methodologie, können wir Sie dabei Unterstützen, eine Read Only Version ganz automatisch im Falle von Downtimes zur Verfügung zu stellen. Damit können Ihre Mitarbeiter:innen weiterhin auf das System zugreifen und sich zu jederzeit wichtige Informationen beschaffen.
Automatischer Update Rollout in gleichbleibenden Zeitabständen
In vielen Unternehmen werden Updates manuell auf aktive Systeme aufgespielt und es werden bereits im Vorfeld Zeitpunkte festgelegt, an denen ein Update aufgespielt wird.
Viele Updates laufen im Hintergrund und beeinträchtigen die Verfügbarkeit des Systems nicht oder nur für kurze Augenblicke. Doch einige Updates erfordern es, das Systeme für einige Stunden heruntergefahren werden müssen.
Durch die Implementierung von Automatismen und der Verwendung von DevOps Tools, gehören diese manuellen Schritte der Vergangenheit an.
Wir bei XALT nutzen zum einen die Blue-Green Deployment Methodik und den Ansatz um eine 99,95 % Verfügbarkeit zu gewährleisten. Und zum anderen nutzen wir eine Vorgehensweise, welche fertige Entwicklungssysteme mit der “Grünen” und inaktiven Instanz merged und an einem fest definierten Zeitpunkt veröffentlicht, das heißt von Blue auf Green wechselt.
Damit beschleunigen Sie nicht nur die Zeit von Entwicklung zu Deployment und bieten Ihren Mitarbeitern:innen einen wahren Zeitvorteil, sondern sorgen zudem mit dem ehemaligen Live System (Blue) die Möglichkeit schnell und einfach ein Rollback vorzunehmen.
Sie erkennen einige dieser Probleme bei sich wieder und möchten Herr über die Lage werden? Unseren erfahrenen DevOps Engineers helfen Ihnen dabei gerne weiter und geben Ihnen in einem ersten Gespräch erste Handlungsempfehlungen, wie Sie DevOps bereits frühzeitig integrieren können.
Weitere Informationen zu DevOps finden Sie hier: DevOps Transformation


