
The provision or deployment of Atlassian Software can be done with a number of tools. AWS in combination with Kubernetes and Spinnaker are particularly well suited for this. In the first part of this series, we will focus on infrastructure when deploying Atlassian software with AWS.
By combining the reliability and scalability benefits of Kubernetes with the deployment automation and application management of Spinnaker, we get an environment where we can freely deploy different types of applications. Without having to worry about how and where they are deployed in the infrastructure.
This deployment solution defines layers for development and operation and responsibilities separately. This way, everyone knows about the surrounding applications and the deployment process. This allows you to then focus on the tasks in the designated tier.
Here is an example of this deployment workflow:
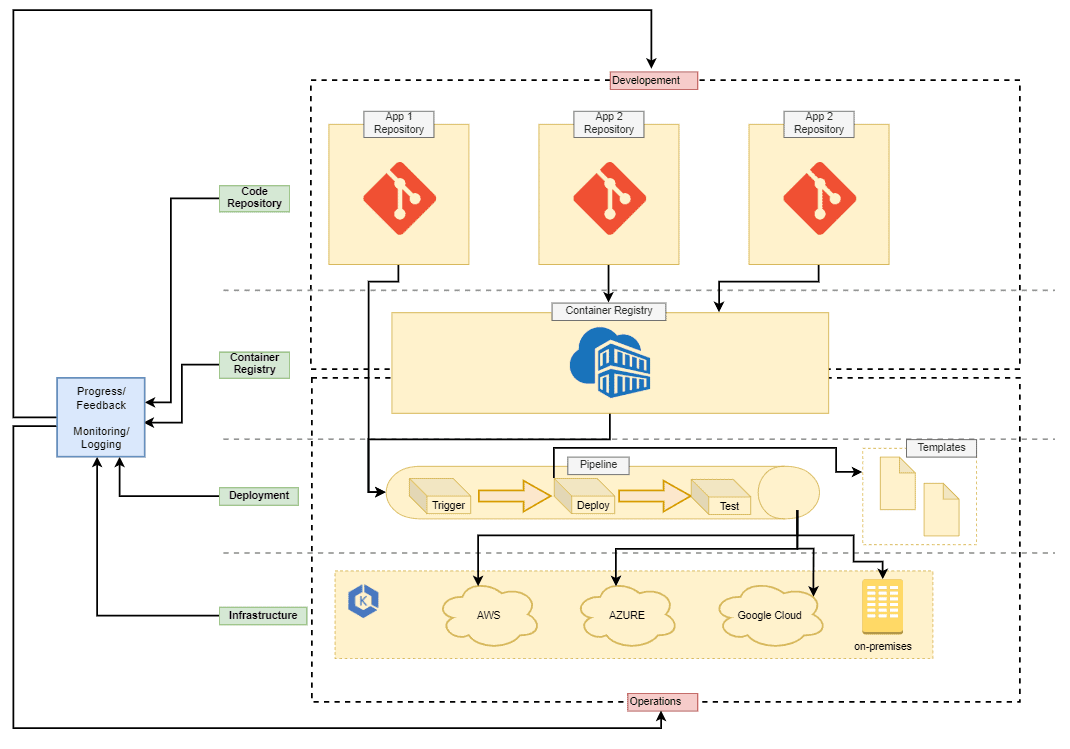
In this graph we see four infrastructure levels of deploymentCode Repository, Container Registry, Deployment and Infrastructure. When a developer needs to deploy an application or create a new environment for his project, he should not need to go to the Deployment or Infrastructure layer for that. So rather Operations part should provide interfaces in the form of code repositories that allow a developer to work in his environment. This will allow Operations to act as the administrator for the deeper deployment layers, layout rules, and process automation with the deployment tools and pipelines of its choice. Development and Operations should still be aware of the entire deployment workflow and have access to all tools.
Automatisms at every level
The automations extend across all layers of the infrastructure. This creates a maintained and carefully planned pipeline to build, test and deploy applications securely. As a result, development and operations are able to follow everything that happens live during each deployment and can also access aggregated information via monitoring, logging and feedback loops.
Containers for all applications
For this whole concept to work, all applications need to be containerized. The idea behind this concept is to standardize and automate the deployment of applications as much as possible to speed up the development and release of new features. Then, step by step, the process is built to integrate applications one by one and to replace old legacy installations.
Infrastructure
Kubernetes offers great flexibility and a growing number of integration options. This includes multiple cloud providers, locations and variety of compute nodes, as well as internal networking. As a result, the infrastructure big-picture may vary from the graphic below depending on functional requirements and use cases.
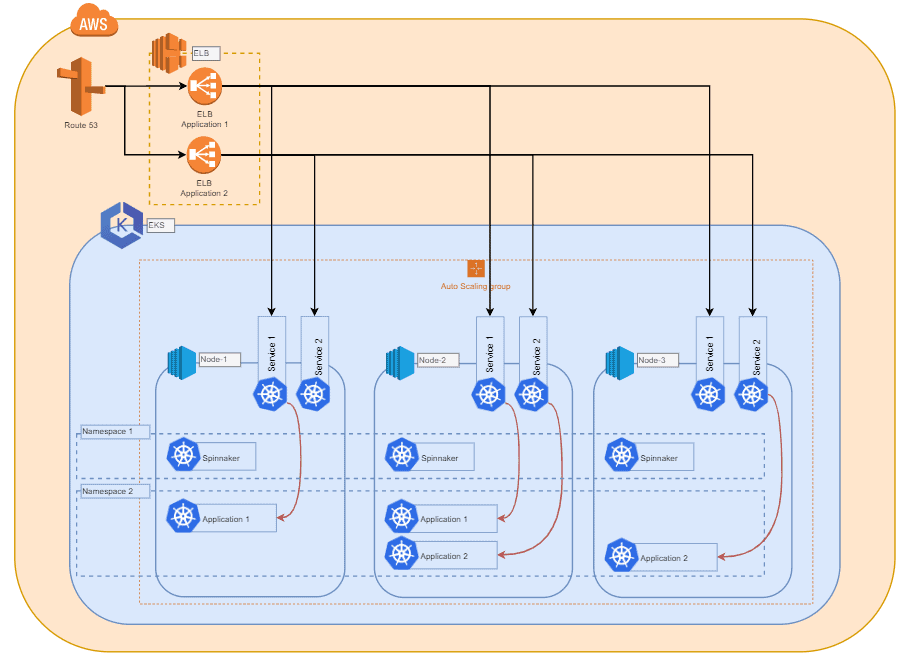
Elastic Kubernetes Service (EKS) from AWS
In this example, we choose EKS as a managed service from AWS, but other managed or even self-hosted Kubernetes systems could also be a valid option.
Since Kubernetes doesn't care about the hardware configuration and deployment of the compute nodes added to a cluster, we can cover a variety of use cases with different requirements. We would recommend choosing an instance type that you are comfortable with and that allows for steady scalability for your applications. The size of this instance type may vary depending on the application you want to deploy. A compute node should be able to hold multiple instances of the application you want to deploy.
Cluster scaling
To enable horizontal scaling of the cluster within the infrastructure, we used AWS Auto Scaling Groups (later referred to as ASG) is used, which is able to spawn new instances and automatically add them to the cluster when a certain load is reached. Depending on the application, you can also implement triggers here that are based on the total RAM and/or CPU load of all compute nodes and that are currently part of the cluster. This way you ensure that the cluster always has enough resources for the deployments. Also, don't forget to add a trigger to scale the cluster back down when the total load of the compute nodes drops again. This way, you can handle load shifts and spikes safely and cost-effectively.
Use of Kubernetes tags
Since Kubernetes works a lot with tags and can deploy deployments based on compute node tags. With multiple ASGs you can set up and scale up different instance types, configurations, and tags. Kubernetes can then deploy projects or applications to hosts with specific tags.
It is also worth mentioning that the compute nodes do not have to exist in the same cloud as the master. Rather, it is possible to combine nodes from different clouds and even on-premises hardware. This requires more work to be put into the overall cluster network configuration
On to Part 2: Deployment →


