
Die Bereitstellung bzw. Deployment von Atlassian Software kann mit etlichen Tools erfolgen. Hier eignen sich gerade AWS in Kombination mit Kubernetes und Spinnaker eignen sich dafür hervorragend. Im ersten Teil dieser Reihe konzentrieren wir uns auf die Infrastruktur bei der Bereitstellung von Atlassian Software mit AWS.
Durch die Kombination der Vorteile der Zuverlässigkeit und Skalierbarkeit von Kubernetes mit dem Bereitstellungsautomatismus und der Anwendungsverwaltung von Spinnaker erhalten wir eine Umgebung, in der wir verschiedene Arten von Anwendungen frei bereitstellen können. Ohne sich Gedanken darüber machen zu müssen, wie und wo sie in der Infrastruktur bereitgestellt werden.
Diese Deployment-Lösung definiert Ebenen für Entwicklung und Betrieb und Verantwortlichkeiten getrennt. Auf diese Weise weiß jeder über die umgebenden Anwendungen und den Bereitstellungsablauf Bescheid. Dadurch kann man sich anschließend auf die Aufgaben in der vorgesehenen Ebene konzentrieren.
Hier ist ein Beispiel für diesen Bereitstellungsworkflow:
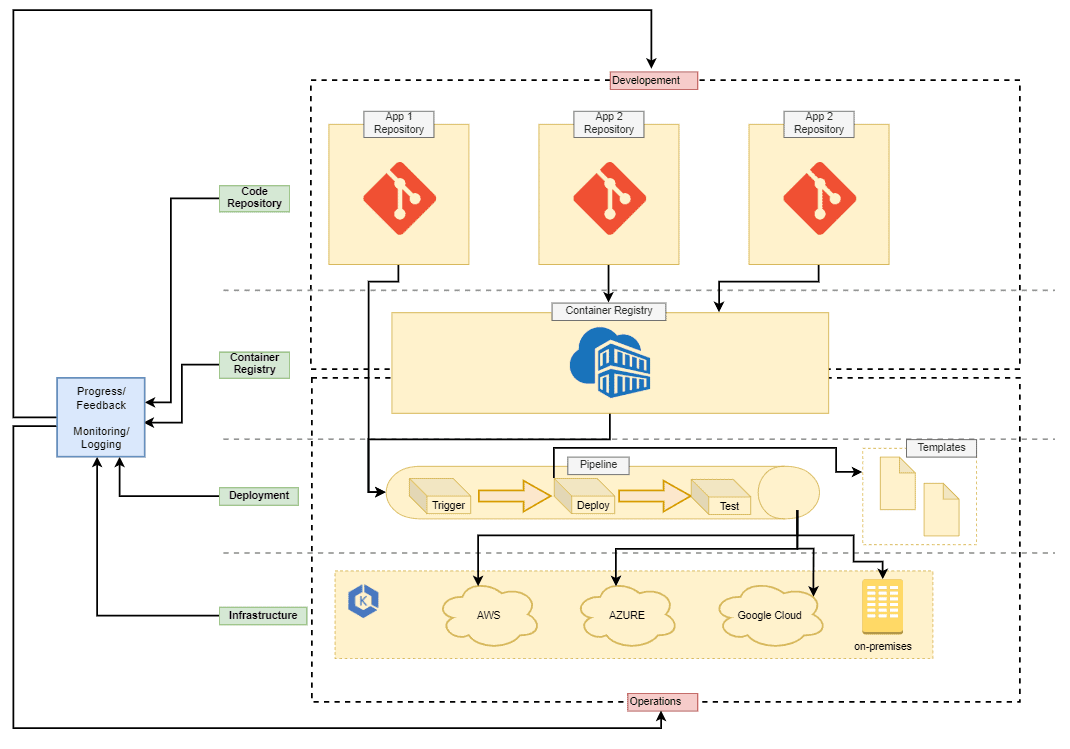
In dieser Grafik sehen wir vier Infrastruktur Ebenen der Bereitstellung: Code Repository, Container Registry, Deployment und Infrastructure. Wenn ein Entwickler eine Anwendung bereitstellen oder eine neue Umgebung für sein Projekt erstellen muss, sollte er dafür nicht in den Deployment- oder Infrastructure-Layer gehen müssen. So sollten vielmehr Operations-Teil Schnittstellen in Form von Code-Repositories bereitstellen, die es einem Entwickler ermöglichen, in seiner Umgebung zu arbeiten. Dadurch wird Operations wird als Administrator für die tieferen Deployment-Schichten, Layout-Regeln und die Prozessautomatisierung mit den Deployment-Tools und Pipelines seiner Wahl fungieren. Entwicklung und Operations sollten dennoch den gesamten Deployment-Workflow kennen und Zugriff auf alle Tools haben.
Automatismen auf jeder Ebene
Die Automatismen erstrecken sich über alle Ebenen der Infrastruktur. So entsteht eine gepflegte und sorgfältig geplante Pipeline, um Anwendungen sicher zu bauen, zu testen und bereitzustellen. Dadurch sind bei jedem Deployment Entwicklung und Betrieb in der Lage, alles, was live passiert, mitzuverfolgen und können über Monitoring, Logging und Feedback-Schleifen auch auf aggregierte Informationen zugreifen.
Container für alle Anwendungen
Damit dieses ganze Konzept funktioniert, müssen alle Anwendungen containerisiert werden. Die Idee hinter diesem Konzept ist es, das Deployment von Anwendungen so weit wie möglich zu standardisieren und zu automatisieren, um die Entwicklung und die Veröffentlichung neuer Funktionen zu beschleunigen. Anschließend wird Schritt für Schritt der Prozess aufgebaut um Anwendungen nach und nach zu integrieren und um alte Legacy-Installationen zu ersetzen.
Infrastruktur
Kubernetes bietet eine große Flexibilität und eine wachsende Anzahl von Möglichkeiten bei der Integration. Dazu gehören mehrere Cloud-Provider, Standorte und Vielfalt von Compute-Nodes, sowie die interne Vernetzung. Daher kann das Big-Picture der Infrastruktur je nach Funktionsanforderungen und Anwendungsfällen von der unten stehenden Grafik abweichen.
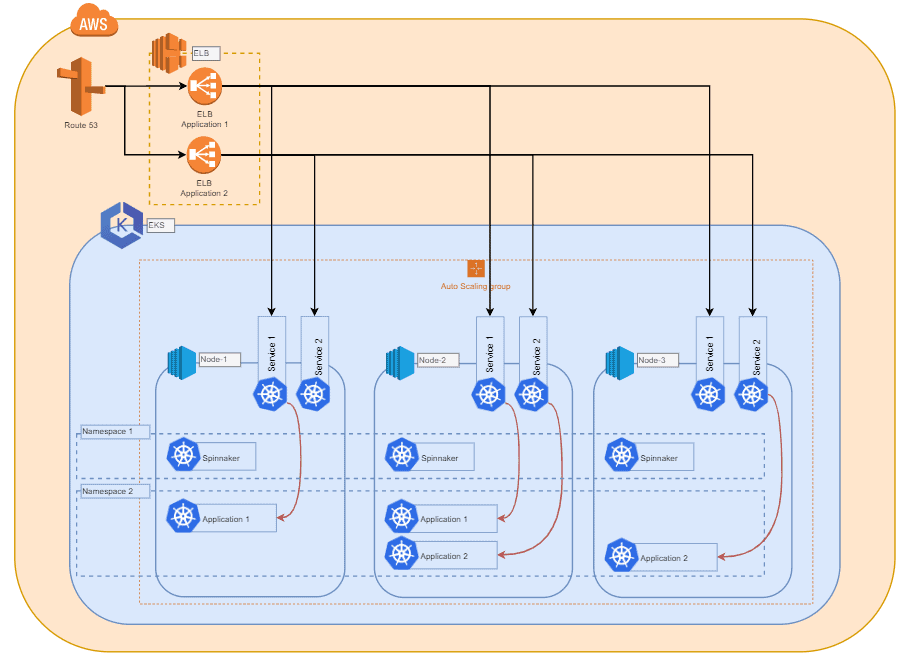
Elastic Kubernetes Service (EKS) von AWS
In diesem Beispiel entscheiden wir uns für EKS als Managed Service von AWS, aber auch andere verwaltete oder sogar selbst gehostete Kubernetes-Systeme könnten eine valide Option sein.
Da sich Kubernetes nicht um die Hardwarekonfiguration und -verteilung der zu einem Cluster hinzugefügten Compute-Nodes kümmert, können wir eine Vielzahl von Anwendungsfällen mit unterschiedlichen Anforderungen abdecken. Wir würden empfehlen, einen Instanztyp zu wählen, mit dem Sie sich wohlfühlen und der eine stetige Skalierbarkeit für Ihre Anwendungen ermöglicht. Die Größe dieses Instanztyps kann je nach der Anwendung, die Sie einsetzen möchten, unterschiedlich sein. Ein Compute-Node sollte in der Lage sein, mehrere Instanzen der Anwendung, die Sie bereitstellen möchten, zu halten.
Skalierung von Clustern
Um eine horizontale Skalierung des Clusters innerhalb der Infrastruktur zu ermöglichen, haben wir AWS Auto Scaling Groups (später als ASG bezeichnet) verwendet, die in der Lage ist, neue Instanzen zu spawnen und sie automatisch zum Cluster hinzuzufügen, wenn eine bestimmte Last erreicht wird. Je nach Anwendung können Sie auch hier Trigger implementieren, die auf der gesamten RAM- und/oder CPU-Auslastung aller Compute Nodes basieren und die aktuell Teil des Clusters sind. Auf diese Weise stellen Sie sicher, dass der Cluster immer genügend Ressourcen für die Deployments hat. Außerdem sollten Sie nicht vergessen, einen Trigger hinzuzufügen, um den Cluster wieder herunterzuskalieren, wenn die Gesamtlast der Compute Nodes wieder sinkt. Auf diese Weise können Sie Lastverschiebungen und -spitzen sicher und kosteneffizient bewältigen.
Nutzung von Kubernetes Tags
Da Kubernetes viel mit Tags arbeitet und Deployments auf Basis von Compute-Node-Tags verteilen kann. Mit mehreren ASGs lassen sich unterschiedliche Instanztypen, Konfigurationen und Tags einrichten und hochskalieren. Kubernetes kann dann Projekte oder Anwendungen auf Hosts mit bestimmten Tags deployen.
Erwähnenswert ist auch, dass die Compute Nodes nicht in der gleichen Cloud wie der Master existieren müssen. Vielmehr ist es möglich, Nodes aus verschiedenen Clouds und sogar On-Premises-Hardware zu kombinieren. Dafür ist es erforderlich, mehr Arbeit in die gesamte Cluster-Netzwerkkonfiguration zu investieren
Weiter zu Teil 2: Deployment →


