
There are several options for Atlassian hosting. Server, Data Center or even directly in the Atlassian Cloud. One of these options is to host Atlassian software directly on your own server or at the AWS / Azure (cloud provider) to host.
In this short article you will find all the information and requirements for hosting Atlassian software.
Atlassian Hosting: Requirements
Official domain with a DNS server where records can be added and resolved.
DNS records pointing to the external IP of the server on which the Atlassian application is to run.
If route 53 is used, we can use certbot and letsencrypt to generate wildcard certificates for the entire domain.
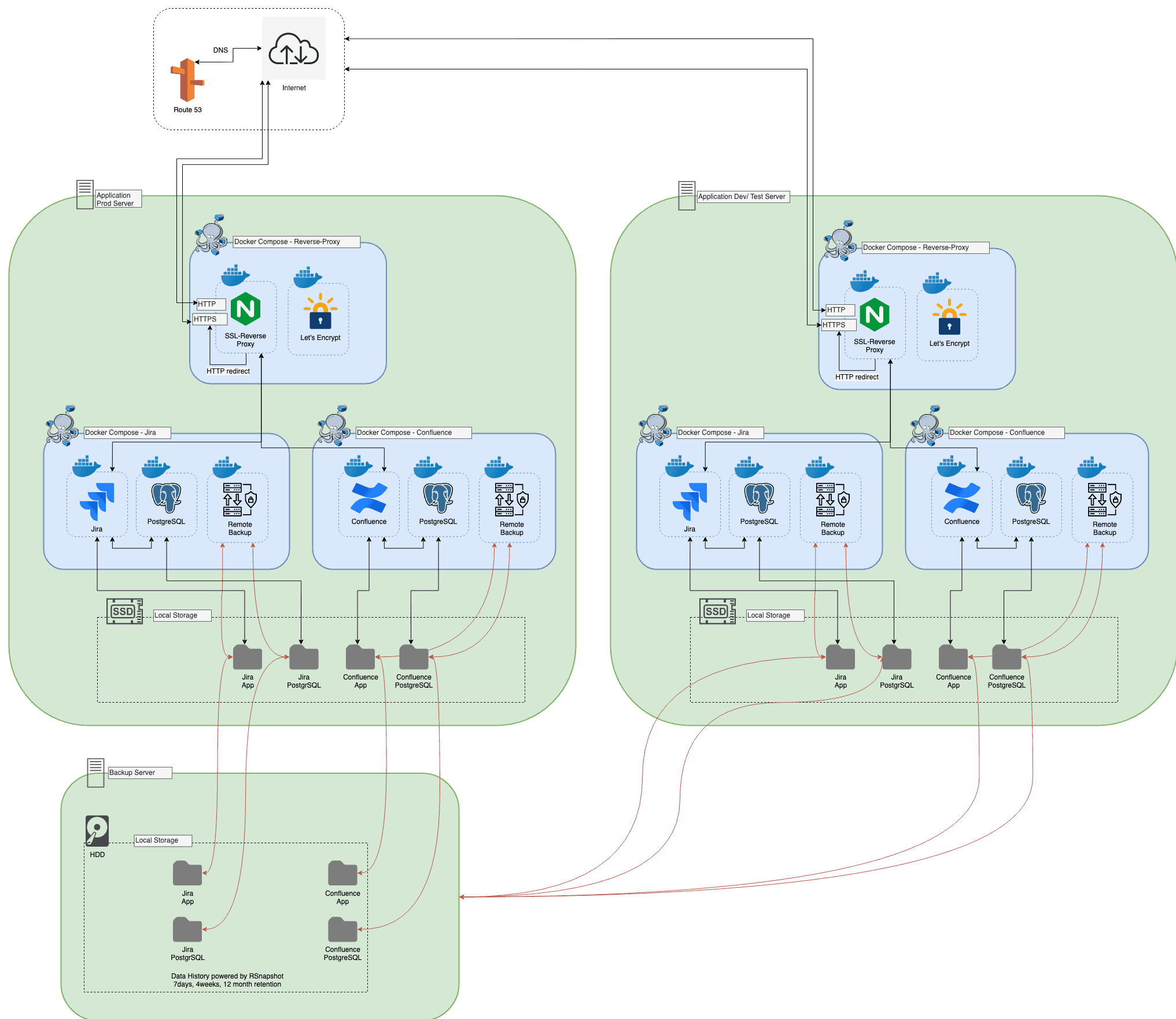
Application server
Server provisioning
As an application server, we usually use Ubuntu and run Ansible to configure it. Ansible then does some basic configuration and installs needed software, like Docker on the host. It also rolls out some Docker applications on a host, like the reverse proxy.
Reverse proxy
We use the Docker image xalt/nginx as a reverse proxy. This can attach to the Docker socket and is thus able to read which Docker containers are running on the host. If an application has certain parameters set, the Nginx configuration is automatically changed and reloaded, upstream and server configurations are created for the specified virtual hostname and ports. If the hostname matches an available SSL certificate, an SSL listener is also configured for that application. The reverse proxy can serve content over 80 (http) and 443 (https), these ports are mounted on host ports 80 and 443.

A side-cart container is provided, the Let's Encrypt helper. This container also has read access to the Docker socket, and when a container provides Let's Encrypt parameters, it initiates a Let's Encrypt certificate challenge and stores the certificates so that the reverse proxy container can use them for the https connections.
Docker application
All Docker applications are described in a docker-compose.yml file provided by Ansible. JIRA/ Confluence and the PostgreSQL database have their home directory included in separate directories at the same level as the docker-compose.yml. This way, the application configuration and the application data are in the same area and can be easily maintained.
JIRA/ Confluence
This Docker container runs a Tomcat with the JIRA application. The Tomcat connector must be configured correctly via environment variables of the container. The same applies to application monitoring via NewRelic. The heap parameters can be configured in the same way and of course the reverse proxy parameters have to be set, as well as the Letsencrypt parameters if required.
For test systems we have implemented a few more features to allow the recovery of persistent home data via ssh rsync and the modification of the database with Liquibase. For example, the base URL or the application links can be changed.
PostgreSQL
We typically use a PostgreSQL container and spawn it in a separate, application-specific Docker network under the DNS name "db", which is only accessible to the containers specified in this docker-compose.yml file. Username, password and database are specified as environment parameters of the container. The database for JIRA/ Confluence can also be MySQL or OracleSQL, but we chose PostgreSQL for compatibility reasons.
For test systems, we implemented a few more features to allow recovery of persistent home data via ssh rsync.
Backup
This container basically runs a cron job that shuts down the JIRA/Confluence and PostgreSQL container and transfers the persistent home folders to the backup server via rsync. This container is also configured by several environment parameters, such as the cron job time, the backup server name, and also needs some mount points, such as the Docker socket, to shut down and start Docker containers from inside a Docker container. Other mounts are also needed to locate where the data to be backed up is located.
Web request
When a Docker application is to be accessed, the user usually enters a DNS name in the browser. The IP attempts to be resolved by a DNS query to R53. The response is usually an A record pointing to the server running the application. The browser establishes a connection to port 80 of the application server. There, the Docker proxy forwards the requests to the Nginx reverse proxy, which redirects to https if a valid certificate exists for the application's virtual hostname. When this directive is executed by the browser, the request is accepted on port 443 at the application server. This goes to the reverse proxy, which then sends it to the configured upstream, the Atlassian application, and delivers the response to the requesting browser to load more resources and render the downloaded web page in the en.
Atlassian Hosting: Backup Server
This host is typically provisioned with large memory to store the application data of multiple Docker applications. It is also provisioned via Ansible.
Here, Docker is not installed by default, but rsync and rsnapshot, which are the most important components for our backup concept. Rsync is used for the data transport from host to host, but also for rsnapshot.
The usual configuration for the retention mechanism allows the storage of 7 daily, 4 weekly and 12 monthly backups. This enforces the use of hard links for the backup to save space if a file has not been touched since the last day.
This way, it consumes about 2.5 times the original application sizes (rsync of the data from the application server to the backup server consumes 1 + the rsnapshot copy of it and the corresponding deltas take another 1.5 times the size) to have backups that can be restored up to 12 months.
More about Managed Atlassian Hosting
The whole concept requires generating an SSH key on the application server and storing the public key in the authorized keys of the backup server's root user:
- Synchronize the data (rsync) from the backup container (application server) to the backup server.
- Rsnapshot is triggered by cronjob logic to run the various retention configurations once per day, week, and month.
- A Docker application is started with the correctly specified backup parameters and will rsync this data from the backup server before the application starts.
The data to be restored can be configured in the Docker container of JIRA/Confluence and PostgreSQL. If the most recent backup is needed, the destination folders of the rsync backup can be specified. However, if data from an older backup is to be restored, we need the correct rsnapshot path here.


