
Wie in Teil 1 beschrieben bietet die Bereitstellung / Deployment von Atlassian Software mit AWS und Spinnaker einige essenzielle Vorteile. Im zweiten Teil geht es darum, wie diese mit Hilfe von YAML Dateien bereitgestellt werden können. Diese enthalten die Konfiguration von Anwendungen.
Bereitstellung auf Basis von YAML Dateien
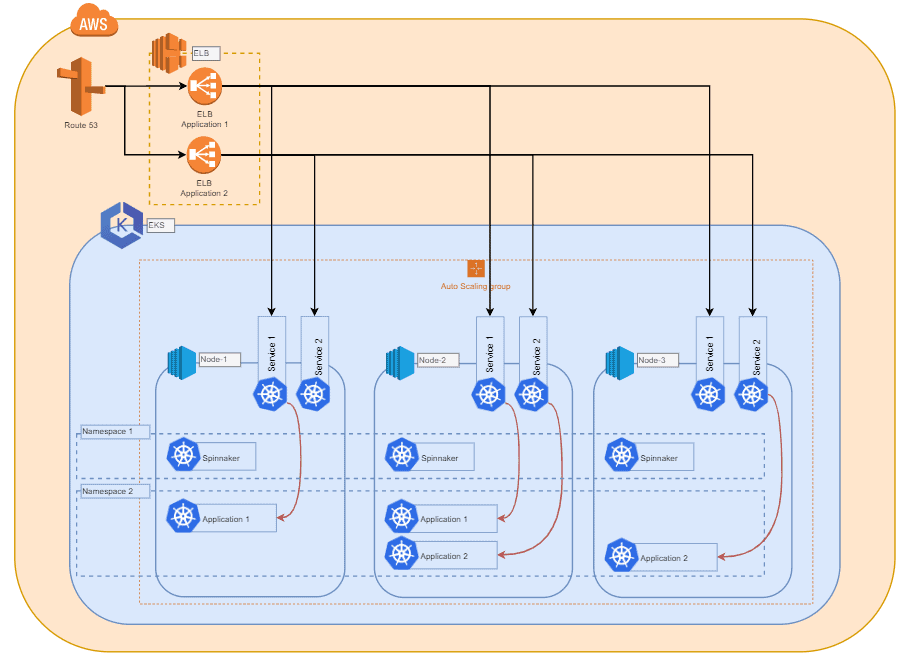
Deployments werden in mit YAML-Dateien durchgeführt, in denen die Konfiguration von Anwendungen, Diensten und mehr für Kubernetes festgelegt wird. Diese sollte weiterhin zum einen einen Namen, eine Definition dessen, was man bereitstellen möchte, und zum anderen die Anzahl der Replikate enthalten. Wenn wir zum Beispiel eine Fail-Save-Anwendung auf Kubernetes deployen wollen, würden wir 2 Komponenten einsetzen.
1. Die Anwendung
Zunächst die Anwendung selbst. Da wir sie ausfallsicher machen wollen, würden wir sie in Form eines “ Replica-Sets“ mit 3 Replikaten bereitstellen. Kubernetes beginnt dann mit dem Deployment von 3 Pods mit der beschriebenen Anwendung und verteilt diese auf die Compute Nodes. Dies geschieht anhand von Hardwarebeschränkungen und Tags.
2. Der Service
Die zweite Komponente ist ein „Service“. Man kann ihn sich wie einen Loadbalancer innerhalb des Clusters vorstellen. Zudem sorgt dieser Dienst nun für den Lastausgleich auf allen unseren drei Pods. Dies geschieht auf der Grundlage bestimmter Tags, die wir in der Deployment-Yaml angegeben haben. Je nach Service-Typ kann EKS einen AWS Loadbalancer mit einem öffentlichen Domain-Namen erzeugen. Dadurch können wir ohne manuelle Netzwerkanpassungen auf unsere Anwendung zugreifen. Weiterhin ist es auch möglich, Ingress-Controller bereitzustellen und unsere Anwendung mit anderen Tools erreichbar zu machen.
Verwendung von Spinnaker
Jeder, der Zugriff auf den Cluster hat, kann nun Anwendungen manuell bereitstellen. Daher entwickeln wir eine Methode, um alle Deployments für jeden, der damit arbeitet, transparent zu machen und Deployments über einen standardisierten und zuverlässigen Weg zu kanalisieren.
Hier kommen Spinnaker und seine Pipelines ins Spiel. Diese geben uns einen Überblick über die im Cluster laufenden Anwendungen. Außerdem können wir so einfach weitergehende Informationen über Bereitstellungen wie Deployment-Versionen, Pipeline-Läufe oder den Status des Loadbalancers erhalten. Spinnaker selbst wird in den Cluster bereitgestellt. Dadurch profitiert Spinnaker von der gleichen Ausfallsicherheit, die Kubernetes für alle Anwendungen unter dessen Kontrolle bietet.
DevOps hilft ihrem Unternehmen dabei noch effzienter und effektiver Software Lösungen auszuliefern und Ihre Kunden durch konstante Updates von sich zu überzeugen. Mehr über DevOps erfahren.
Infrastruktur aus Microservices
Die Idee ist hier, eine Infrastruktur zu haben, die aus containerisierten Microservices besteht. Jeder Microservice/Applikation wird aus einem dedizierten Repository gebaut und nachdem Änderungen vorgenommen wurden, wird die Applikation gebaut, die dann für den Build eines neuen Docker-Images verwendet wird. Dieses Image wird in eine private Docker-Registry gepusht.
Spinnaker Pipeline
Dies löst eine Spinnaker-Pipeline aus, die nun den geänderten Container mit der bereitgestellten Konfiguration als neue Version in den Cluster einspielt und den Service Loadbalancer so ändert, dass er den Datenverkehr nur auf die neu deployte Version leitet. Wenn diese Version die eingebauten Prüfungen nicht besteht, wird die Änderung rückgängig gemacht und die alte Version wieder über den Service Loadbalancer aktiv gesetzt.
Idealerweise stellt die Spinnakers-Pipeline alle Container zunächst in einer Dev/Stage-Umgebung bereit, um auf Fehler zu prüfen, bevor die Änderungen in der Master/Production-Umgebung bereitgestellt werden. Ein fehlgeschlagenes Update kann dadurch automatisch und auch manuell über die Spinnaker-Web-UI rückgängig gemacht werden.
Sie möchten mehr über Atlassian Hosting auf AWS erfahren? Hier gehts zu unseren Cloud Hosting Services


